- Read Me는 읽어보셨나요? -
2023.02.17 - [HakBu Review (학부)/Computer Architecture] - Read Me
● 명령어 파이프라이닝
명령어 파이프라이닝(Instruction Pipelining) : 명령어를 실행하는데 사용하는 하드웨어를 독립적인 단계(stage)들로 분할하고, 그들로 하여금 동시에 서로 다른 명령어들을 처리하도록 함으로써 CPU 성능을 높여주는 기술.
- 2단계 파이프라이닝
: 인출 단계와 실행 단계로 나누어 구성
명령어가 실행되는 동안 다음 명령어가 인출되고, 다음 명령어가 실행되는 동안 그 다음 명령어가 인출되는 식으로 진행됨.
다음에 실행될 명령어를 미리 인출하는 것을 명령어 선인출(Instruction Prefetch) 혹은 인출 중복(Fetch Overlap)이라고 함.
이론상 1.5배의 속도향상을 기대할 수 있지만, 이는 명령어의 인출과 실행에 같은 길이의 시간이 소요되는 경우만 해당되며, 실제로는 실행 단계에서 더 오래 걸리기 때문에 실행을 기다리느라 인출이 지연되어 기대만큼의 속도 향상이 이루어지지 않음.
- 4단계 파이프라이닝
: 명령어 인출, 명령어 해독, 오퍼랜드 인출, 실행의 4단계로 이루어진 파이프라인
각 단계의 소요 시간이 거의 같음.
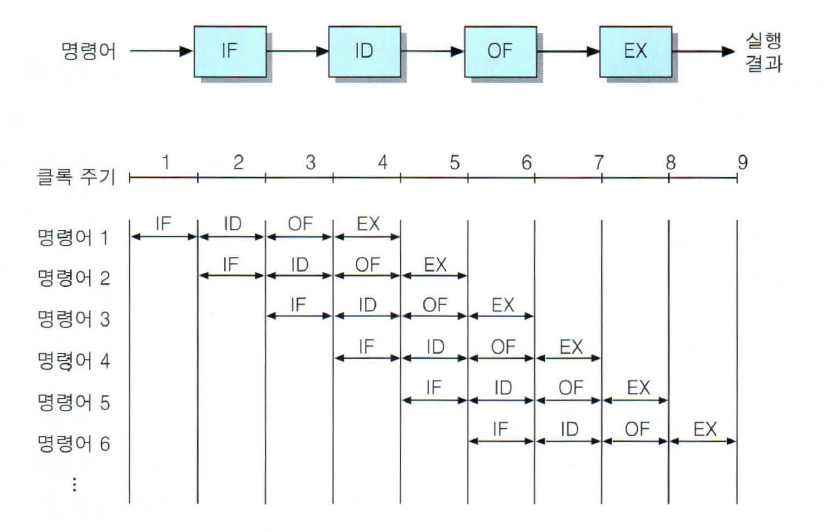
파이프라이닝을 이용한 경우 전체 명령어 실행 시간을 T,
파이프라인 단계 수를 k,
실행할 명령어 수를 N이라 하면,
T는 다음과 같음.
T = k + (N-1) # 첫 명령어를 실행하는데 k 단위시간 만큼 걸리고, 그 다음부터는 1 단위시간 만큼 걸리기 때문.
만약 파이프라인이 되지 않았다면 N개의 명령어를 실행하는데 k×N만큼의 시간이 걸리므로 속도향상(Sp)는 다음과 같이 표현 가능함.
Sp = (미적용 시 소요시간)/(적용 시 소요시간) = (k × N) / {k + (N - 1)}
위 식에 따르면 k단계 파이프라인을 이용하면 최대 k배의 속도 향상을 얻을 수 있음.
하지만 이를 방해하는 근본적인 문제점들이 존재함.
1. 안 거쳐도되는 오퍼랜드 인출단계가 있음.(=불필요한 시간이 소모됨)
2. 단위 시간은 가장 오래 걸리는 단계를 기준으로 정해져야 함.(=빨리 끝난 단계는 시간 낭비가 생김.)
3. 명령어 인출과 오퍼랜드 인출이 출돌할 수 있음. 모두 기억장치에 액세스하는 단계이기 때문.
4. 조건 분기 명령어가 실행되면 처리중이던 명령어들이 무효화되고 효율이 확 낮아짐.
완전한 해결은 어렵지만, 보완을 위해 10단계 이상의 슈퍼파이프라이닝 기술을 사용하고, CPU 내부 캐시를 명령어 캐시와 데이터 캐시로 구분함.
또한, 조건 분기 성능 저하 최소화를 위해 분기 예측, 분기 목적지 선인출, 루프 버퍼, 지연 분기 등의 기술을 이용함.
※ 루프 버퍼 : 인출 단계에 포함되어 있는 작은 고속 기억장치, 가장 최근에 인출된 일정 개수의 명령어들이 순서대로 저장되어 잇다. 분기 발생시, 분기 목적지의 명령어가 버퍼에 있는지 확인 후 있으면 버퍼로부터 인출함.
※ 지연 분기 : 분기 명령어의 위치가 최대한 뒤로 가도록 재배치
- 슈퍼스칼라
: CPU의 처리 속도를 더 높이기 위해 내부에 두 개 혹은 그 이상의 명령어 파이프라인들을 포함시킨 구조. 이론적으로 처리 속도가 파이프라인의 수만큼 높아질 수 있음. m개의 파이프라인으로 이루어진 구조를 m-way 슈퍼스칼라라고 부름.
+ 유의할 점
명령어들이 서로 영향을 받지 않고 독립적으로 수행될 수 있어야 함.(= 데이터 의존성이 존재하지 않아야 함)
m-way 슈퍼스칼라 프로세서가 N개의 명령어를 실행하는데 걸리는 전체 시간 T(m)은 다음과 같음.
T(m) = k + (N - m) / m # 처음 m개를 실행하는데 k 단위시간만큼 걸리고, 그 뒤로 매 주기마다 m개씩 실행됨.
속도 향상을 계산해보았을 때, 명령어가 많아질 수록 m배에 가까워지며, 파이프라인을 사용하지 않은 프로세서에 비해 mk배까지 향상됨.
- 듀얼 코어 및 멀티 코어
CPU 코어 : 기존의 CPU 칩에 포함되던 하드웨어 중 명령어 실행에 반드시 필요한 핵심 모듈, 슈퍼스칼라 모듈과 ALU 및 레지스터 세트 등을 말함.
멀티 코어 프로세서 : CPU 코어 여러 개를 하나의 칩에 넣은 것. 2개는 듀얼~, 4개는 쿼드~, 6개는 헥사~, 8개는 옥타~ 등으로 부름.
각 CPU코어는 내부 캐시와 시스템 버스 인터페이스만 공유함. 따라서 각 코어는 프로그램을 동시에 독립적으로 수행하며(= 멀티태스킹) 필요한 경우에만 공유 캐시를 통해 정보를 교환함.
+ 멀티 쓰레딩(Multi-threading)
쓰레드 : 독립적으로 실행될 수 있는 최소 크기의 프로그램 단위.
레지스터 세트(실행 중인 쓰레드의 시스템 상태와 데이터 및 주소 정보를 저장 가능)가 여러 개인 경우 한 코어에서 여러개의 쓰레드를 동시에 처리할 수 있고, 이를 멀티 쓰레드라고 함.
'Computer Science > Computer Architecture' 카테고리의 다른 글
| 3. 컴퓨터 산술과 논리 연산 (1) (0) | 2023.02.23 |
|---|---|
| 2. CPU의 구조와 기능 (3) (0) | 2023.02.21 |
| 2. CPU의 구조와 기능 (1) (0) | 2023.02.19 |
| 1. 컴퓨터시스템 개요 (2) (0) | 2023.02.19 |
| 1. 컴퓨터시스템 개요 (1) (0) | 2023.02.18 |



